Personal project · 2026
Briney Family Tree: An AI-Driven Genealogical Research Engine
An agent-powered research pipeline that scans the Briney family GEDCOM for promising leads, investigates each across cached and primary sources, and produces a human-reviewable findings report before anything touches the tree.
The brief
Genealogy is one of those domains where the bottleneck is not writing — it’s checking. A finite number of public databases hold a lot of the answers; the work is figuring out which person is which, where the dates don’t line up, who’s missing a death record, which immigrant founder needs a closer look, which famous-cousin link is real and which is wishful thinking.
An LLM agent is actually good at most of that. The trick is keeping it on a leash: the GEDCOM stays the single source of truth, and nothing gets written without a human in the loop.
What it does
Target identification
A research session starts by scanning the GEDCOM for the kinds of patterns a genealogist would notice:
- Missing birth or death dates
- Zero-lifespan anomalies and date discrepancies
- Broken parent/child or spousal links
- Immigrant founders with unresolved origins
- Military service that could anchor a record
- Plausible “famous-cousin” links worth verifying
Multi-source investigation
For each target, the agent works through a layered set of sources:
- A local WikiTree cache for the family branches
- FamilySearch and Find A Grave
- Wikipedia for notable connections
- Targeted web search for primary-source citations
- A growing corpus of published family-history books
Findings — not edits
The agent doesn’t write to the tree. It produces a findings report: per target, what it found, the sources, a confidence band, and a proposed GEDCOM edit. I review and approve. Approved edits run through a bio_guard step that protects existing biographical narrative from being clobbered.


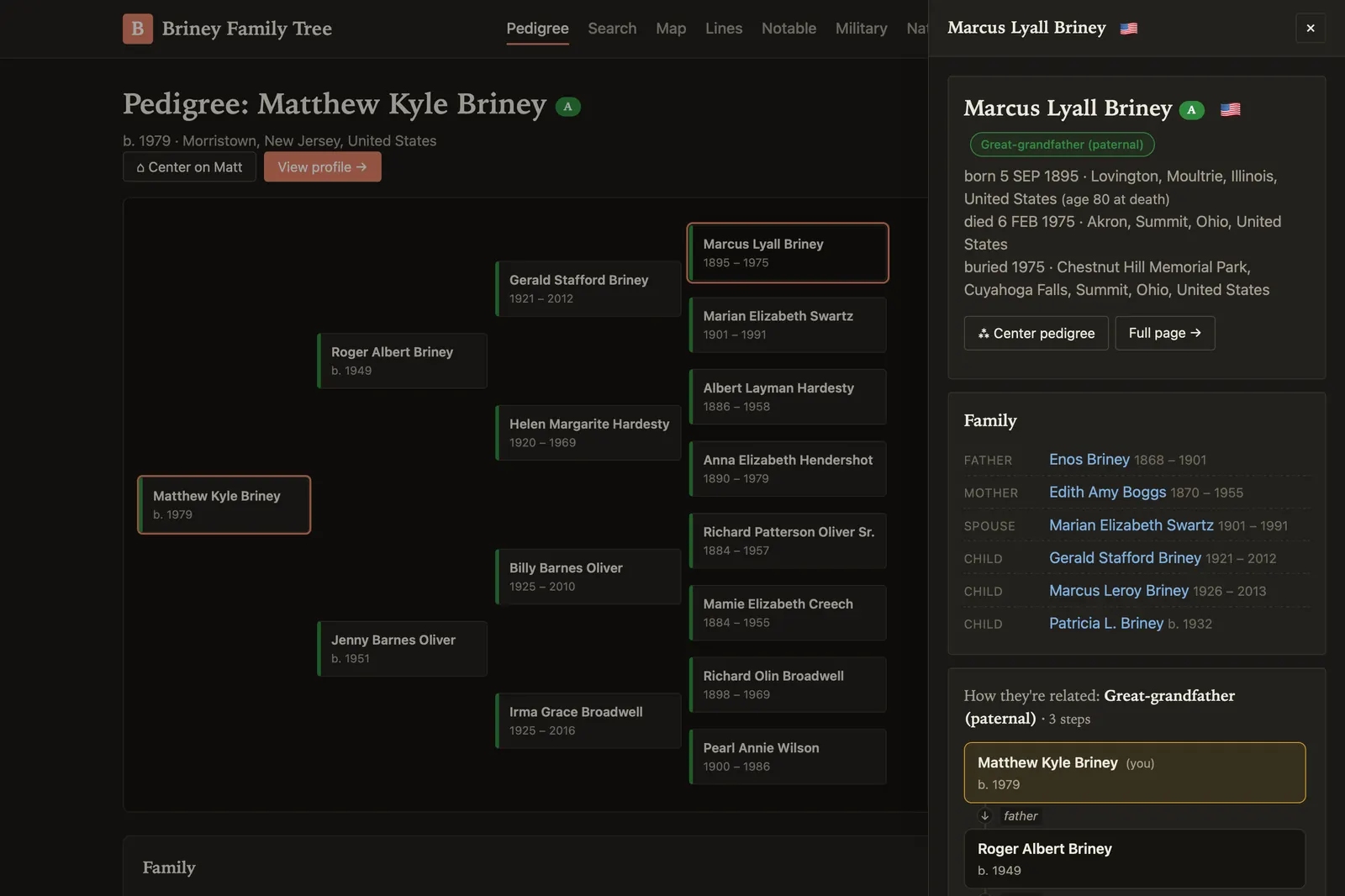
The frontend
The tree itself is a custom static site — a pedigree explorer with search, map, lines-of-descent, and notable-ancestor features, plus a sources-and-confidence panel that makes the AI’s reasoning visible rather than hidden. Migration paths show up on a map. Everything links to the underlying citation.
Why I like it
An agent that can surface 100 candidate facts in an hour, with sources and confidence, turns a hobby that used to take years into something you can move forward on a Sunday afternoon.
It’s also a useful working example of where I think this technology actually belongs in cultural-heritage settings: as a research-assistant layer over real archival material, with the human in the loop and the institution’s data as the ground truth.